Today I’m very excited to announce the release of graffiti, a Python library for declarative graph computation. To get going with graffiti, you can either install from PyPI via pip or checkout the source and install it directly:
1 2 3 4 5 6 7 | |
If you’d like to jump right in, the README has a brief introduction and tutorial. Also check out Prismatic’s Plumbing library which served as a huge source of inspiration for graffiti.
the problem
Consider the following probably entirely reasonable Python snippet:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
This somewhat contrived example demonstrates two interesting ideas. First, it’s
very common to build a computational “pipeline” by starting with some initial
value (xs above) and pass it through a series of transformations to reach our
desired result. Second, the intermediate values of that pipeline are often
useful in their own right, even if they aren’t necessarily what we’re trying to
calculate right now. Unfortunately the above example breaks down in a couple of
key aspects, so let’s examine each of them in turn. Afterwards, I’ll show how
to represent the above pipeline using graffiti and discuss how some of these
pitfalls can be avoided.
One function to rule them all
The first obvious issue with our stats function is it’s doing everything. This
might be perfectly reasonable and easy to understand when the number of things
it’s doing is small and well-defined, but as the requirements change, this
function will likely become increasingly brittle. As a first step, we might
refactor the above code into the following smaller functions:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
Is this code an improvement over the original? On the one hand, we’ve pulled out
a bunch of useful functions which we can reuse elsewhere, so that’s an obvious
+1 for reusability. On the other hand, the stats_redux function is still
singularly responsible for assembling the results of the other stats functions,
making it into something of a “god function”.
Furthermore, consider how many times sum and len are being called compared
to the previous implementation. With the functions broken apart, we’ve lost the
benefit of local reuse of those intermediate computations. For simple
examples like the one above, this might be a worthwhile trade-off, but in a real
application there could be vastly more time consuming operations where it would
be useful to build on the intermediate results.
It’s also worth considering that in a more complex example the smaller functions
might have more complex arguments putting a higher burden on the caller. For
this reason it’s convenient to have a single (or small group of) functions like
stats_redux to properly encode those constraints.
Eager vs. lazy evaluation
Another significant issue with the original stats function is the eagerness
with which it evaluates. In other words, there isn’t an obvious way to compute
only some of the keys. The simplest way to solve this problem is to break down
the function as we did in the previous section, and then only manually compute
the exact values as we need them. However, this solution comes with the same set
of caveats as before:
- We lose local reuse of [potentially expensive to compute] intermediate values.
- It puts more burden on the user of the library, since they have to know and understand how to utilize the utility functions.
One possible approach to solving this problem is to manually encode the dependencies between the nodes to make it easier for the caller, but also allowing parts of the pipeline to be applied lazily:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
The above code might seem silly (because it is), but it solves the problem of
eagerness by breaking the computation down into steps that build on eachother
linearly. We also get reuse of intermediate values (such as len) essentially
for free. The biggest issues with this approach are:
- It basically doesn’t work at all if the computational pipeline isn’t perfectly linear.
- It might require the caller to have some knowledge of the dependency graph.
- It doesn’t scale in general to things of arbitrary complexity.
- The steps aren’t as independently useful as they were in the previous section due to the incredibly high coupling between them.
When the source ain’t enough
The final issue I want to discuss with our (now beaten-down) stats function is
that of transparency. In simple terms, it is extremely difficult to understand
how xs is being threaded through the pipeline to arrive at a final result.
From an outside perspective, we see data go in and we see new data come out, but
we completely miss the relationships between those values. As our application
grows in complexity (and it will), being able to easily visualize and reason
about the interdependencies of each component becomes extraordinarily important.
Unfortunately, all of that dependency information is hidden away inside the body
of the function, which means we either have to rely on documentation (damned
lies) or we have to read the source. Furthermore,
reading the source is rarely the most efficient way to quickly get an intuition
about what the code is actually trying to do.
Complexity [in software systems] grows at least as fast as the square of the size of the program
- Gerald Weinberg, Quality Software Management: Systems Thinking
In my experience, there isn’t a good general solution to this problem. Some applications reify certain kinds of dependencies in the type system. Others will use patterns like Dependency Injection or Inversion of Control to push dependency information into the application configuration or framework container. However, as the application tends towards complexity, these solutions can become just as brittle or pathologically difficult to understand as their imperative counter-parts.
graffiti to the rescue!
Here’s a quick recap of the issues we’ve identified so far about stats:
- It’s doing too much stuff, but we’d like to have a single (or small number) of functions responsible for building the results we want.
- It eagerly evaluates all of its results, but we’d like to be able to ask for some subset of those keys.
- It’s hard to see how the final dictionary/map is being generated and, in particular, what the dependencies between the different values are.
- Pulling it all apart has potential performance implications if intermediate values are computed multiple times.
Let’s rewrite stats to use graffiti:
1 2 3 4 5 6 7 8 9 10 11 12 | |
So what’s going on here? stats_desc is a “graph descriptor”, or in other words
a description of the fundamental aspects of our computational pipeline. The
Graph class accepts one of these descriptors (which is just a simple
dict/map), and compiles it into a single function that accepts as arguments the
root inputs (xs in this case), and then builds the rest of the graph according
to the specification.
Ok, so this just seems like an obtuse way to represent the stats function.
But because we’ve represented the pipeline as a graph, graffiti can do some
incredibly useful operations. For example, you can visualize the graph:
1 2 | |
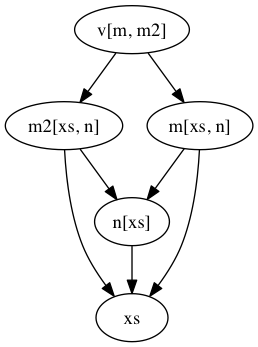
Or we can ask it to partially evaluate the graph for only some of its keys:
1 2 | |
We can even resume a previously partially computed graph:
1 2 3 | |
Graphs can be nested arbitrarily, provided there are no dependency cycles:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
Graph descriptors are just normal dicts/maps, so non-dict/non-function values work normally:
1 2 3 4 5 6 7 8 9 | |
Graphs can accept optional arguments:
1 2 3 4 5 6 7 8 9 10 | |
Lambdas in Python are quite limited as they are restricted to a single expression. Graffiti supports a decorator-based syntax to help ease the creation of more complex graphs:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | |
So how does this stack up to our stats function?
- Too much stuff –> each node is responsible for one aspect of the overall computational graph.
- Eager evaluation –> graffiti can partially apply as much of the graph as necessary, and you can incrementally resume a graph as more values are required.
- Hard to see dependencies –> graffiti’s powerful visualization tools give you an amazingly useful way to help gain an intuition about how data flows through the pipeline. Moreover, since the graph is just a dict, it’s easy to inspect it, play with it at the repl, build it up iteratively or across multiple files/namespaces, etc.
- Performance penalties from decoupling –> everything stays decoupled and intermediate values are shared throughout the graph. graffiti knows when not to evaluate keys if it already has done previously making graphs trivially resumable (see #2).
Hopefully some of these examples have demonstrated the power graffiti gives you
over your computational pipeline. Importantly, since graph descriptors are just
data (and the Graph class itself is just a wrapper around that data), you can
do the same fundamental higher-order operations on them that you can normal
dictionaries. And I’ve just started scratching the surface of what graffiti
can do!
If you’re interested in helping out, send me a note SegFaultAX on Twitter and Github.